
Linear regression is a fundamental statistical technique to understand the relationship between two variables. It works on the principle of fitting a straight line through data points to model the relationship between the independent variable and the dependent variable(s).
This topic isn’t always taught in depth to anyone that hasn’t had rigorous mathematical training. So, in a series of posts I will go over in depth some of the fundamental concepts of linear regression. Please refer to the previous post over the fundamental concept of model assumptions, if you haven’t already.
The Simple Linear Regression Model and its Components
This post considers the simple linear regression model, a model with a single regressor x that has a relationship with a response variable y that is a straight line.
y = β0 + β1x + ϵ
Where β0 is the intercept and β1 is the slope, and we call these the regression coefficients. The component ϵ represents random error.
| Component | Definition |
|---|---|
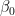 |
Intercept – If the range of data on x includes x = 0, then the intercept is the mean of the distribution of y when x = 0. If the range of x does not include 0, then the intercept has no practical interpretation. |
 |
Slope – the change in the mean of the distribution of y produced by a unit change in x. |
| ϵ | Random error |
| Y | The dependent or response variable |
| X | The independent or predictor variable |
Linear Regression Model Assumptions
For this model to be valid, there are several assumptions that the model has about the underlying data:
- Linearity: The relationship between X and Y is linear
- Independence: The error terms are independent of each other.
- Homoscedasticity: The error has constant variance
- Normality: The residuals are normally distributed with mean 0.
Thus, for the model to yield unbiased estimates of β0 and β1, then these assumptions must not be violated.
Estimation of Linear Regression Parameters
The parameters β0 and β1 are unknown and must be estimated using a sample dataset. This data may be the result from a controlled experiment, from an observational study, or from historical records.
The method of least squares is a technique used to estimate the parameters of a model by minimizing the differences between the data points and the predicted values. We use this method to find the best-fitting line that describes the relationship between the X variable and the Y variable. In other words, the method of least squares is used to estimate β0 and β1 so that the sum of squares of the differences between the observations yi and the straight line is minimum.
Least Squares Estimators
The first equation we referred to as the simple linear model, or a population regression model, is y = β0 + β1x + ϵ. Suppose we have n pairs of data, (y1, x1), (y2, x2), …, (yn, xn). From the first equation, we can write yi = β0 + β1xi + ϵi, i = 1, 2, …, n, which is the sample regression model, written in terms of n pairs of data.
Mathematically, we want to minimize:

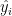
Residuals play a key role when investigating model adequacy and in detecting departures from model assumptions, however, these concepts will be discussed more in-depth in further posts.
Additionally, this sum represents the total squared vertical distance between each observed point and the corresponding point on the fitted regression line.
Deriving the Normal Equations
To estimate β0 and β1, we differentiate the above equation with respect to each parameter and set the derivatives equal to zero. We refer to the resulting equations as the least squares normal equations. These equations provide the estimates for the parameters.
- Partial derivative with respect to β0:

- Partial derivative with respecting to β1:

We can now simplify these to obtain the normal equations:


Essentially, these two equations represent the two unknowns β0 and β1, and solving them gives the least squares estimates.
Solving the Normal Equations
The solutions for the parameters β0 and β1 are:
, where
and
are the means of the X and Y values, respectfully.

Therefore, the above two equations are the least squares estimators of the intercept and slope, respectively. So the fitted model is now:

Since the denominator of the equation for 



Understanding the Least Squares Normal Equations
The normal equations are essentially a system of linear equations derived from minimizing the sum of squared residuals. Solving these equations provides the estimates 
In summary:
- The first normal equation ensures that the sum of the residuals is zero. This means that the average of the observed values yi is equal to the average of the predicted values
- The second normal equation balances the relationship between X and the residuals. This ensures that the weighted sum of the residuals (weighted by the X values) is also zero, ensuring that the line is as close as possible to the data points in terms of minimizing the total error.
Simple Linear Regression Example
Rocket Propellant
A rocket motor is manufactured by bonding an igniter propellant and a sustainer propellant together inside a metal housing. An important characteristic of the bond between the two types of propellant is the shear strength. It is suspected that the shear strength is related to the age in weeks of the batch of the sustainer propellant. We have twenty observations on the shear strength and age of a corresponding batch.
Here is a look at the data:
| Observation | Shear Strength (psi) | Age (weeks) |
|---|---|---|
| 1 | 2158.7 | 15.5 |
| 2 | 1678.15 | 23.75 |
| 3 | 2316 | 8 |
| 4 | 2061.3 | 17 |
| 5 | 2207.5 | 5.5 |
| 6 | 1708.3 | 19 |
| 7 | 1784.6 | 24 |
| 8 | 2575.9 | 2.5 |
| 9 | 2357.9 | 7.5 |
| 10 | 2256.7 | 11 |
| 11 | 2165.2 | 13 |
| 12 | 2399.55 | 3.75 |
| 13 | 1779.5 | 25 |
| 14 | 2336.75 | 9.75 |
| 15 | 1756.3 | 22 |
| 16 | 2053.5 | 18 |
| 17 | 2424.4 | 6 |
| 18 | 2200.5 | 12.5 |
| 19 | 2654.2 | 2 |
| 20 | 1754.7 | 21.5 |
Let’s make a scatter plot of the shear strength and age variables to see if the linear assumption is reasonable.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
rocket_data = pd.read_excel(r'\...\rocket_data.xlsx')
plt.scatter(rocket_data['Age (weeks)'], rocket_data['Shear Strength (psi)'])
plt.xlabel('Age (weeks)')
plt.ylabel('Shear Strength (psi)')
plt.savefig('rocket_scatter.png')
plt.show()
This plot suggests there is a strong statistical relationship between shear strength and age. The assumption of the linear relationship seems to be appropriate.
So, now let’s estimate the model parameters.
Estimating model parameters
To estimate the parameters, let us first calculate:

and

Therefore, from the calculations of 


and

So the least-squares fit of the model is:

We may interpret the slope -37.296 as the average weekly decrease in shear strength of the propellant due to the age. Since the lower limit of the x‘s is near the origin, the intercept 2,629.85 represents the shear strength in a batch of propellant immediately following manufacture.
Thus, if we take our original data, plug the x values into the fitted equation, we get the value for 
Observed value, 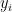 | Fitted value, | Residual,  |
| 2158.7 | 2051.762354 | 106.9376463 |
| 1678.15 | 1744.070561 | -65.9205612 |
| 2316 | 2331.482165 | -15.48216516 |
| 2061.3 | 1995.818391 | 65.48160853 |
| 2207.5 | 2424.722102 | -217.2221023 |
| 1708.3 | 1921.226442 | -212.9264418 |
| 1784.6 | 1734.746567 | 49.85343251 |
| 2575.9 | 2536.610027 | 39.28997314 |
| 2357.9 | 2350.130153 | 7.769847416 |
| 2256.7 | 2219.594241 | 37.10575941 |
| 2165.2 | 2145.002291 | 20.19770912 |
| 2399.55 | 2489.990058 | -90.44005829 |
| 1779.5 | 1697.450593 | 82.04940737 |
| 2336.75 | 2266.214209 | 70.53579084 |
| 1756.3 | 1809.338517 | -53.03851719 |
| 2053.5 | 1958.522417 | 94.97758339 |
| 2424.4 | 2406.074115 | 18.32588513 |
| 2200.5 | 2163.650278 | 36.84972169 |
| 2654.2 | 2555.258014 | 98.94198572 |
| 1754.7 | 1827.986505 | -73.28650462 |
 = 42,629.65 = 42,629.65 |  = 42,629.65 = 42,629.65 |  = 0.00 = 0.00 |
The Residuals
We can see from the table, that the sum of the residuals is 0.00. Recall that the residuals represent the part of the observed data that the model doesn’t capture, showing the deviation (also called the error) between the real outcome and what the model predicts (the line). When the residuals sum to 0, it means that the regression model’s predicted values are, on average, equal or close to the observed values.
It implies that the regression line has been positioned such that it minimizes the overall error and balances the differences between the observed and predicted values across the data points. However, it doesn’t necessarily mean that the model is a perfect fit; the residuals can still vary widely even though their total is zero.
Simple Linear Regression Questions
After getting the least-squares fit, there are some questions we can investigate before the model is deployed:
- How well does the model fit the data?
- Is the model likely to be useful as a predictor?
- Are any of the model assumptions (like constant variance and uncorrelated errors) violated? If so, how serious is this?
As mentioned earlier, residuals play an integral role in evaluating model adequacy. They can be viewed as realizations of the model errors, ϵi.
In order to check the assumptions of constant variance and uncorrelated errors, we must investigate if the residuals look like a random sample from a distribution with these properties. We will dive into these topics and questions in a later post, where we perform model adequacy checking.
Properties of Least Squares and the Fitted Model
We need to determine the statistical properties of least-squares estimators if we wish to use them to make statistical inferences.
Furthermore, the least squares estimates
- Unbiased: The estimators
- Minimum Variance: By the Gauss-Markov theorem, under the assumptions of linearity, independence, and constant variance (but not necessarily normality), the OLS estimators are the best linear unbiased estimators (BLUE).
- Efficiency: If we assume normality of the errors ϵ, the least squares estimates are also maximum likelihood estimators, making them the most efficient estimators under normality.
- The sum of the residuals in any regression model that contains an intercept is always zero (as demonstrated in the previous example).
- The least-squares regression line always passes through the centroid of the data. That is, the point
.
Unbiased Estimators
To show that the least squares estimators for β0 and β1 are unbiased, we need to demonstrate that the expected value of the estimators equals the true parameter values. In order to do this, it is essential to understand the theorems of expectation and variance, discussed in more detail in another post.
Estimation by Maximum Likelihood
The method of least squares can be used to estimate the parameters in a linear regression model regardless of the form of the distribution of the errors. This method produces best linear unbiased estimators of β0 and β1 . If the form of the distribution of the errors is known, then an alternative method may be used to estimate the parameters known as the method of maximum likelihood.
Note that if the errors are normally distributed, then the maximum likelihood estimation and least-squares will produce the same estimates of the parameters.
The Likelihood Function
First, given the normality assumption, the probability density function of the errors is:

The likelihood function is the product of these probabilities for all observations, 

Note: To simplify the math, we typically work with the log-likelihood function:

Consider data 

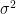
![L(y_i, x_i, \beta_0, \beta_i, \sigma^2) = \prod_{i=1}^n (2\pi \sigma^2)^\frac{-1}{2} exp[-\frac{1}{2\sigma^2} (y_i - \beta_0 -\beta_1 x_i)^2]](https://s0.wp.com/latex.php?latex=L%28y_i%2C+x_i%2C+%5Cbeta_0%2C+%5Cbeta_i%2C+%5Csigma%5E2%29+%3D+%5Cprod_%7Bi%3D1%7D%5En+%282%5Cpi+%5Csigma%5E2%29%5E%5Cfrac%7B-1%7D%7B2%7D+exp%5B-%5Cfrac%7B1%7D%7B2%5Csigma%5E2%7D+%28y_i+-+%5Cbeta_0+-%5Cbeta_1+x_i%29%5E2%5D&bg=ffffff&fg=000&s=0&c=20201002)
![= (2\pi \sigma^2)^\frac{-1}{2} exp[-\frac{1}{2\sigma^2} \sum_{i=1}^n (y_i - \beta_0 -\beta_1 x_i)^2]](https://s0.wp.com/latex.php?latex=%3D+%282%5Cpi+%5Csigma%5E2%29%5E%5Cfrac%7B-1%7D%7B2%7D+exp%5B-%5Cfrac%7B1%7D%7B2%5Csigma%5E2%7D+%5Csum_%7Bi%3D1%7D%5En+%28y_i+-+%5Cbeta_0+-%5Cbeta_1+x_i%29%5E2%5D&bg=ffffff&fg=000&s=0&c=20201002)
The goal is to maximize the log-likelihood with respect to β and σ2. By setting the derivative of the log-likelihood with respect to β equal to zero, you can derive the maximum likelihood estimates (MLE) for β, which turns out to be the same as the ordinary least squares (OLS) estimates. We will go more in-depth on these calculations in a later post.
Properties of MLE
In general, maximum-likelihood estimators have better statistical properties than least-squares estimators. The maximum-likelihood estimators are unbiased and have minimum variance when compared to all other unbiased estimators. They are also consistent estimators (consistency is a large-sample property indicating that the estimators differ from the true parameter value by a very small amount as n becomes large), and they are a set of sufficient statistics (this implies that the estimators contain all of the “information” in the original sample of size n).
On the other hand, maximum-likelihood estimation requires more stringent statistical assumptions than the least-squares estimators. The least-squares estimators require only second-moment assumptions (assumptions about the expected value, the variances, and the covariances among the random errors). The maximum-likelihood estimators require a full distributional assumption, in this case that the random errors follow a normal distribution with the same second moments as required for the least-squares estimates.
Estimation of σ2
In addition to estimating the intercept β0 and slope β1, an estimate of σ2 is important. This estimate is critical for conducting hypothesis tests and constructing confidence intervals pertinent to the model.
Ideally, we would like this estimate not to be dependent on the adequacy of the fitted model. However, this is only possible when there are several observations on y for at least one value of x, or when prior information concerning σ2 is already known.
When this is not true, the estimate is obtained from the residual or error sum of squares, which measures the unexplained variation in the observed values after fitting the regression line.
The variance of the error terms σ2 is estimated by averaging the squared residuals. To obtain an unbiased estimate, we divide by the number of observations minus the number of parameters estimated (degrees of freedom):

- n is the number of observations
- p is the number of parameters, including the intercept.
Example with Rocket Propellant Data
Formulas:
- 92,570,846.55 – ((42629.65)2/20) = 1,706,493.591
- From this, we can find the residual sum of squares
- 1,706,493.591 – (-37.30)(-41,270.21) = 167,280.85
- Therefore, the estimate of σ2 can be computed as:
= 9,293.38
- Where 18 comes from n – 2 to account for the degrees of freedom.

*Note that some calculations may be slightly different due to rounding.
Wrap Up – Simple Linear Regression
In this overview of simple linear regression, we covered the key concepts and techniques for modeling the relationship between two variables. We began by outlining the important assumptions of the model, including linearity, independence, constant variance, and normality. From there, we delved into estimating the parameters using the method of least squares, deriving the normal equations to find the best-fitting line. We also touched on maximum likelihood estimation (MLE) and how it aligns with least squares under certain conditions. To bring these ideas to life, we demonstrated parameter estimation using rocket propellant data, showing how these calculations can provide insight into real-world data.
What’s Next?
In our next post, we’ll explore how to use these parameter estimates for hypothesis testing and building confidence intervals, further enhancing the model’s utility in statistical inference.